For Loops: Using i++, ++i, Enumerators, or None of the Above?

It was 1958; IBM was the leader in creating computers that took up entire rooms. Their recent creation, the IBM 704, was projected to only sell six units and was priced accordingly. When it ended up selling well over 100 units, it helped propel the careers of its two lead designers. Gene Amdahl, from whom we get Amdahl’s Law (which is still a hot topic), led the hardware design. John Backus, the B in BNF, was responsible for leading a team to define and develop an implementation of Fortran that would help ease programming on the system. It offered a choice besides writing in the 704’s assembly language.

One of the newest features of their design was what would later be referred to as the “for loop.” I say “later,” because at the time of its introduction, it was really a “do loop” in syntax, but it had the modern day meaning of a for loop.
As a programmer, you’d sit down at a typewriter-like device called a keypunch, and would type out a line like “310 DO 400 I=1,50” that would tell the compiler that “starting at line 310, keep executing code until you get to line 400, then increment the ‘I’ variable and start all over until ‘I’ exceeds 50, then stop by jumping to the line right after 400.”
There are several things to note about that last statement. The first is that the idea of a “for loop” is over 50 years old. The second is that since there were only 72 characters of usable space on the 704’s card reader, the syntax had to be incredibly terse. Due to the design of language, “I” was the first integer variable available for use (“N” was the last, all others were floating point). Like it or not, this is probably the driving reason why you were taught to write statements like “for(int i = 0; i < 50; i++)” It’s only convenient that “I” is also the first letter in “index” and “iterator.” Computer programming teachers and books inevitably all trace back to Fortran.
I’m sure that as a programmer you’ve written thousands of for loops in your life. If you’re a professional programmer, you’ve probably read thousands of for loops written by other people. If you do this long enough, you’ll likely come across several different styles.
The first style is by far the most popular. We can illustrate it by an example. Let’s say that we have a list of presidents of the United States and we want to know how many presidents have a last name that is longer than six letters. You might have a program that has a helper class like this:
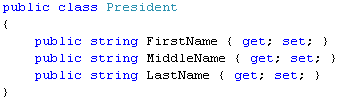
You’d then create and initialize a list of Presidents explicitly or from a file/database:

Finally, you’d be able to have your dear friend, the for loop:

We’ve all written code like this. It’s so easy you don’t even have to think about it.
Right? Well, let’s think about it just for fun.
The second style would be to do something like this:

Did you catch the difference? The first style used the post-increment (i++) operator for the for-iterator and the latter one used the pre-increment (++i) operator. Most of the world uses the post-increment notation because that’s what we all saw in our textbooks and online samples. People that use the second notation are usually very particular about it. Almost all of them come from a C++ background. The reason is that in the Standard Template Library (the C++ rough equivalent of the .net Base Class Library) has the concept of iterators that allow you to go through a data structure like a vector. In the implementation of the post-increment operator on the iterator, one needs to preserve a copy of the old value and then increment the value and return the old value to keep with the proper meaning of the operator in language specification. The post-increment operator is usually implemented by calling the pre-increment operator with the added tax of keeping the old value. Typically users of the “++i” style will come back at you and say something like “i++ is so wasteful! You’ve got that copy that you aren’t even using! Shame on you buddy!”
Ok, maybe that’s a bit extreme. But it could happen.
But, let’s check out the truth for .net code. In this particular situation, is it wasteful? Let’s look at the IL instructions for the post-increment (i++) version of our “for loop” using ILDASM (with my comments on the right):

Now, to save time, let’s see how the above compares with the pre-increment (++i) version:
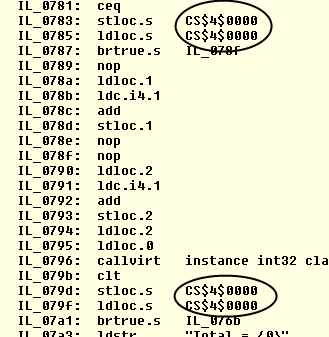
There you have it folks. The code is the exact same except for how the C# compiler names the throw-away variable used for checking inequalities. This has absolutely no effect on performance. All other instructions are exactly identical. The C# compiler sees that no one cares about preserving a copy of the value, and makes a decision to ignore that. This is so basic of a technique that this happens even in debug builds. In case you’re wondering, we couldn’t have just done a simple diff on the two EXEs even if the C# compiler emitted the same code because .net compilers place a Module Version Identifier (MVID) GUID that is different every time you compile your assembly.
Anyways, with all due respect, any C++ compiler worth its file size would perform the same optimization trick (for integer types). Like I said, the only real difference came with iterators. In .net, we don’t have the exact equivalent of iterators, but we do have Enumerators. This allows us to change the code above to look like this:

Notice that we got rid of “i” completely! However, it’s just slightly less efficient from a performance perspective. The reason is that the compiler turns this into a call to the List’s GetEnumerator() which in turn does this:
Which just punts to this method:

Now, during the actual enumeration/iteration, the code will call MoveNext() that looks like this:

There are two things that I found interesting. The first is that there is a check on a “_version” field to see if it’s different and if so, throw an error. After doing some reflectoring, it turns out that any time you modify a List through calls to methods like Add or Remove, the “_version” member gets incremented. This tells the class that it’s been changed. If you changed the List after creating the Enumerator, you’ll get this unfriendly error message:

This design is ultimately caused by the second interesting thing in the code above. If you look carefully, you’ll see that the core of MoveNext is exactly the same as the “for loop” style mentioned earlier. We have a “this.index” variable that gets incremented on every call and then we check to make sure that the index is less than “list._size”. If the List is modified, the “this.index” might not make sense, and therefore an exception needs to be thrown.
After all enumeration is done, there is a call to dispose the Enumerator. Therefore, the “foreach” syntax is roughly rewritten to this code by the compiler:

which just makes me even more thankful for the C# “foreach” syntax sugar.
Clearly the “foreach” method takes more instructions and performs a generation 0 memory allocation and therefore is slightly slower than the “for loop” method. However, it’s more readable and intuitive. It lets you focus on the problem at hand (enumerating) rather than having to worry about things like the size of the List or being explicit with incrementing an index.
Can we go even better than “foreach”? Absolutely!
I’m sure you’ve even seen “foreach” a lot in production code for the reasons I mentioned. However, it’s very repetitive and boring to have explicitly tell the computer to go through the List looking for a match.
Some programmers might have noticed that List

The messy delegate notation in C# 2.0 made this approach hardly more elegant.
With lambda expressions and type inference, we can rewrite the above statement as:

This really didn’t buy us too much. It’s still a bit messy. The final solution would be to use the LINQ Count extension method to get code like this:

Now we’ve actually made some progress! We’ve compressed all of the work to one clean line of code.
That was a long journey! Congratulations if you made it this far. Was it worth the investment?
Lessons Learned
- When you don’t care about what the specific item offset/index number is, prefer a foreach since it’s cleaner and not that much more expensive.
- Sometimes you can’t use a foreach because you need to know index number (e.g. going through two lists of the same size at the same time). This might be a better candidate for the “classic” for loop. However, don’t bother with using a pre-increment operator because it’s not the way the vast majority of people does it and it doesn’t buy you any performance improvement.
- If performance is absolutely critical, use a for loop as it avoids the Enumerator allocation. You’ll note that the source code for the .net Base Class Library tends to avoid “foreach” because it has been aggressively optimized for performance. It has to sacrifice readability for performance because the BCL is used everywhere. However, it’s likely that your code doesn’t have that type of strict performance requirement. Therefore, favor readability.
- It is worth your time to look at the LINQ extension methods like Count, Sum, Min, Max, Where, OrderBy, and Reverse. It’s amazing how these can dramatically simplify 6-7 lines down to a single line.
- By using the new extension methods, you’ll be able to quickly take advantage of upcoming technologies like Parallel LINQ. Say you had a billion presidents and 4 cores. You’d just simply change your code to “presidents.AsParallel().Count(..)” and your code would scale automatically to all processors.
- In short, consider thinking outside of “for loops” prefer to think at a higher level. One day, you just might be able to honestly say that you’ve written your last “for loop.”
One last thing: as Backus was developing Fortran, John McCarthy was developing LISP. Although the two languages started at roughly the same time, they had notably different design philosophies. Fortran was designed with a bottom-up style that was slightly higher than the raw assembler, but it was fast. LISP was deeply entrenched in the symbolic world of lambda calculus. It was powerful, but slow at first. Many of LISP’s ideas are just now entering into common practice with popular languages like Python, Erlang, F#, and as we saw in the code above, C# 3.0.
So it seems that in 1958, two roads diverged in a wood and LISP became the road less traveled by. At least now, fifty years later, our industry is starting to bridge those two paths. Maybe Anders is right saying that in 10 years, it’ll be hard to categorize languages like C# because they will have deeply incorporated both paths.
But I can’t help but think what programming would be like now had Fortran become the road not taken.
P.S. In case you care, there are 23 presidents of the United States who have a last name longer than 6 letters.