OMeta#: Who? What? When? Where? Why?
What if programming language implementations were object-oriented? What if you wanted to change one itty-bitty part of your favorite language? Say you wanted to add an exponentiation operator (^^). How hard would it be?
Wouldn’t it be nice if you could “subclass” a language like C# and then add 5 lines of code to make it work and then use it? What if you could add Ruby-like method_missing support in 20 lines?
What if you could conceive of a new language and start experimenting with it in production code in an hour? What if it leveraged your knowledge of existing frameworks like .NET?
Let’s imagine that it were possible. Let’s say someone else created a basic calculator-like “language”:
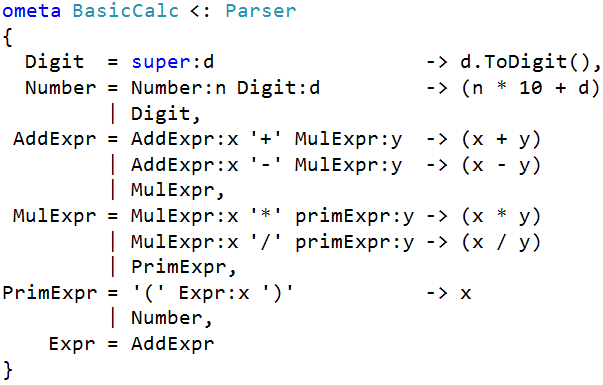
Even without knowing the syntax, you can probably figure out how it works since it’s written very close to the standard way of describing a language. If you give this language “34”, it will respond with 12. If you give it “2^(34)”, it’d respond with a nice syntax error message like “I don’t know how to deal with the ‘^’ symbol. Sorry!”
But you could make it work by writing this object-oriented-like “subclass” of the language:

Now, giving this language “2^(3*4)” happily gives you 4096.
This worked using simple inheritance. What if you wanted to compose your language from several other languages? That is, something like “multiple inheritance” but without its problems? What if we took a simpler approach and allowed a language to attempt to match elements of any other language?
Let’s say we want to build a scientific calculator that leverages some of the work we’ve already done. Instead of inheriting from it, we’ll call out to it:

Now you can calculate expressions like “sqrt (1+2^3)!”
What if such a meta language (e.g. a language for describing other languages) existed? What would you do with it? How might it help you get things done while producing extremely small, but very readable code? What if creating a new language that perfectly fit a problem your software was trying to solve was as easy as writing a simple regular expression?
What if you could get all the whiz-bang, gotta-have tool support like syntax highlighting, interactive debugging, and a compiler for it came at almost no extra cost? What if the barrier to entry for a new language was so low, that almost anyone could do it quickly?
This is what I’ve been thinking about for the past month or so.
Who? & What?
When I was doing some research for my “Towards Moore’s Law Software” series, I came across a very interesting language called OMeta which was created by Alessandro Warth and Ian Piumarta with some inspiration from Alan Kay. In their 2007 Dynamic Languages Symposium paper, the authors described OMeta as
”.. a new object-oriented language for pattern matching. OMeta is based on a variant of Parsing Expression Grammars (PEGs) —a recognition based foundation for describing syntax—which we have extended to handle arbitrary kinds of data. We show that OMeta’s general-purpose pattern matching provides a natural and convenient way for programmers to implement tokenizers, parsers, visitors, and tree transformers, all of which can be extended in interesting ways using familiar object-oriented mechanisms. This makes OMeta particularly well-suited as a medium for experimenting with new designs for programming languages and extensions to existing languages.”
To be honest, I didn’t really understand the paper when I first read it. It sounded cool, but it used a few new terms I hadn’t heard of before. However, I couldn’t help but be fascinated by OMeta’s readable syntax. OMeta doesn’t try to solve every problem involved with writing a complete program. It makes no claims about being a good general purpose programming language. But it positions itself by doing just one thing really well:
Pattern matching.
If you look at modern programming languages that are good for developing other languages, you’ll notice that they usually have good pattern matching capabilities. For example, in ML (which stands for meta-language), you can specify functions in terms of patterns. Here’s how you can reverse a list:
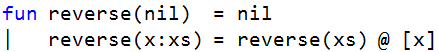
This defines the function named “reverse.” When it sees the “pattern” where the function is called with an empty list (nil), it just returns nil. However, when the function is passed in a list whose first element is “x” and the rest of the list is “xs”, it will return the reverse of the rest of the list and then append the head of the list to the end.
If you think about it for a second, it’s a really compact way of expressing how to reverse a list.
Streams of Anything
What I find interesting about OMeta is how it matches patterns. OMeta can operate on a stream of anything. This is useful because modern language implementations have several phases that work on different types of “things.” Here’s a simplified view of what a compiler does:
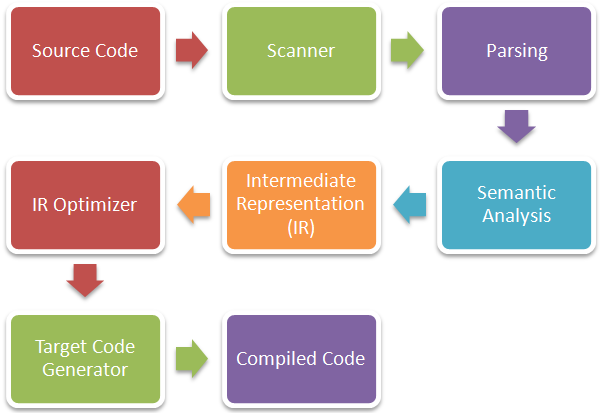
At the start of the process, you’re working with individual characters from source code. The list of characters is converted to tokens by use of a scanner. This is how the characters ‘i’, ‘n’, and ‘t’ become the “INT” token. The next phase combines tokens together to form a higher level view of the program, typically using a tree data structure. From that phase, several intermediate steps occur on the program (almost always in tree form), until it’s finally pulled apart to make an executable program.
Often, you have to use different tools at each phase. You might use lex for the scanner (aka “lexer”), Yacc for the parser, and some sort of visitor pattern in your implementation language (e.g. C#) for many of the intermediate phases. With all of these different tools to learn, it’s no wonder why most people don’t even bother trying to create their own language.
OMeta is different in that lets you use the same syntax for all phases. The only thing that is different is what the input stream contains. At the start, the input stream is characters. In subsequent phases, it tokens, then trees, and then finally you produce your intended result. At each pass, your OMeta code has similar syntax.
Passing the Match Around
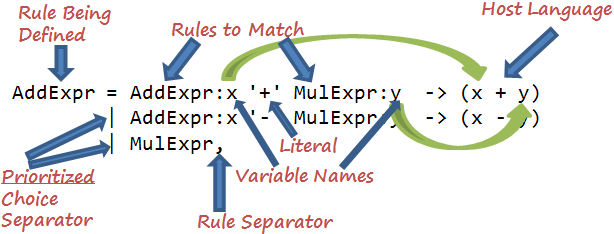
Another interesting bit about OMeta is how it goes about finding rules. Rules are defined in grammars which behave like classes in an object-oriented language. A grammar can “inherit” from another grammar. An added twist is that a grammar can call out to a “foreign” grammar. This makes it easier to build a language from many different reusable parts and allows for trivial “mashups” of several languages.
Additionally, if a rule has multiple “choices,” then OMeta always tries to match the first choice, then the second, and so on until it achieves success. Although this seems obvious in hindsight, most parsers don’t have prioritized choices and thus they make it easy to define ambiguous rules. For example, is “1-2-3” equal to “(1-2)-3” = -4 or “1-(2-3)” = 2? With prioritized choice, you make this explicit. If it successfully parses, then it has exactly one choice and therefore no ambiguities.
The last really interesting aspect of OMeta’s design is what it does when it matches a pattern. A pattern might consist of several sub-components. Each of these components (e.g. rules) can be captured into a variable. OMeta then feeds these variables into a “host” language.
OMeta doesn’t care what the host language is. It can be just about any language (e.g. JavaScript, LISP, C++, etc.). Typically, the host language is what the OMeta implementation itself was written in. The host language is free to do whatever it likes with the variables. OMeta is only responsible for getting them there. The OMeta paper describes an implementation where the host language is cola. Other early versions were written in Squeak and use that as the host language.
Alessandro has recently created a JavaScript version where you experiment with OMeta/JS (e.g. JavaScript is the host language) in your browser. It’s a very interesting playground. Some of the demonstrations range from the basic calculator language, to a type checker, to LISP, to even the OMeta compiler and code generator itself and all of them are written in OMeta/JS. The playground website is neat to use because it shows the translated (generated) JavaScript code for the grammar (although the generated code needs to be put through a pretty printer to make any sense of it).
Why the “#” in OMeta#?
After understanding the basics of OMeta/JS, I thought it would be interesting to have the host language be any .NET language. I started to sketch out what this might look like by using my limited JavaScript ability and translating Alessandro’s code to an equivalent functionality in C#. The result was the start of a project that needed a name. “OMeta#” seemed to fit the bill.
Besides, it just sounded better than other .NET-ism alternatives like “NOMeta”, “OMeta.net”, or “IronOMeta.”
Some might ask, “Why .NET?” A subtle reason is that OMeta is useful for code generation. Code generation is a normal part of the .NET ecosystem even if people don’t realize it. When people use the graphical designer in Windows Forms, there is a code generator working behind the scenes writing code for their host language (typically C# or Visual Basic). When people write ASP.NET “.aspx” files, there is a hidden process that takes that HTML-like “language” and compiles it to a real DLL.
For example, ASP.NET transforms this:

Into this generated code:
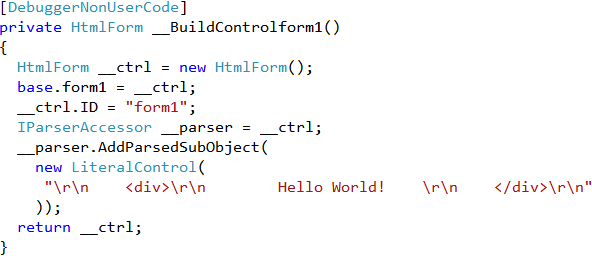
I wanted to bring a similar “it just works” illusion to the .NET world with OMeta#.
With the encouragement of Alessandro, I started working on some of the supporting “goo” that would be required to get OMeta working on the .NET’s Common Language Runtime (CLR). This isn’t trivial because the CLR has stricter type system than languages like JavaScript. Also, since I chose C# as the implementation language, I had to make sure that the code passed all of the static type checking it performs at compile time. It’s been a slow start, but I have been able to make a few steps towards making it work.
One pragmatic question is why even bother adding another language, or rather, meta-language to the .NET world? Why not just get proficient at another toolset that is decent at creating language like ANTLR, Irony, NParsec, or IronRuby? What about using Parsing Expression Grammars in F# or writing Domain Specific Languages in Boo with its extensible compiler pipeline?
Ultimately, all of those tools are pretty good, but none of them did exactly what I was looking for. Some came close, but none of them seem capable of matching OMeta’s power and simplicity.
Another reason was that I knew that writing an implementation of OMeta from the ground up would really help me “know” how it works.
More importantly, I thought it would be fun to work on. I’m not a language expert. I’ll never reach the level of someone like Anders, but I was one of those odd kids that actually liked my compilers and programming languages classes. I also enjoyed the talks from this year’s Lang.NET symposium (even if I didn’t understand a lot of things).
The Grand OMeta# Vision
The grand vision for OMeta# is to make it really simple to create languages that “just work.” It probably won’t have the world’s best performance, but it should be decent enough for almost all practical applications. It would be neat to have OMeta# (or something like it) be used to do the following:
- Serve as a common, unified way for developing languages on the .NET platform — There are many helpful, yet often different “tools” out there for various stages of language design. I mentioned a few earlier, but some of the more advanced ones include the new Dynamic Language Runtime (DLR) and Phoenix compiler framework. It would be neat to have a language that abstracted away some of these tools into a clean syntax like OMeta. That way, you’d get the benefit of these tools without having to constantly learn different ways of manipulating the concepts that can be expressed simply.
- Factor out the “goo” of language development — For a language to be taken seriously, it has to have things like syntax highlighting, interactive debugging, and a decent compiler. Each of these takes time to implement and often involves a high learning curve. It would be great if you could just make some minor annotations to your OMeta grammar and then these features would “just work.”
- Useful for teaching — One of my favorite textbooks in college was “Programming Languages: An Interpreter-Based Approach” by Ramsey (et. al.). Our class used a “draft” version of it (and it still hasn’t been published yet). It took a very interesting approach towards teaching programming languages. In order to understand a language like Scheme, you had to implement an interpreter for it in C or ML. I really liked this approach because getting your hands dirty with implementing the language typically leads to a better understanding of it. I would love to have the ability to implement this type of approach in something like OMeta. You could understand the essence of a language by only having to understand a page or two of code. It would also let you learn by experimenting with adding small features to existing languages.
- Practical for production use — For anything to really succeed at moving towards a Moore’s Law increase in expressiveness, it has to have reasonable quality. I can imagine OMeta# being introduced into real production projects by first integrating a small amount of OMeta’s “generated” a project and then over time implementing more and more parts of the application in this highly specific language. For this to occur, it has to be reliable and simple to use.
When? Where?
All of the parts of the vision are still in the future. To make them a reality will require more than just a single person or even a couple of people. I’m naïve crazy enough to think that it’s actually possible. In an effort not to “go dark,” I’ve decided to be fairly open about the design and implementation of OMeta#. The current state of the code isn’t even alpha quality yet. Despite all of these shortcomings, I’ve posted what I have so far on CodePlex and will continue to make updates to it.
Keeping in the tradition of other OMeta implementations, I’ve licensed it under the MIT License so that you can use, experiment, play, and modify it without any licensing concerns.
The first interesting result is that I’ve been able to get a complete end to end demo working for an extremely simple grammar that matches numbers. I fed this input grammar written in OMeta/C#:

into my OMeta compiler/translator and successfully had it generate this output C# file.
There is still a ton of work left. It’s quite possible that some of the design decisions I’ve made so far need to be challenged and redesigned. I’d love to get feedback from anyone that’s interested.
What do you think? Do you think OMeta fills a unique niche? Do you think it would be useful to have as a tool in .NET? Would you want to help out making “The Grand OMeta# Vision” happen? If so, what parts can you help out with?
I’m curious to hear your thoughts. In my next post, I hope to cover some of the technical details for how my current implementation works “under the covers.”
P.S. Many thanks to Alessandro Warth for creating this beautiful language and helping me get started!