How .NET Regular Expressions Really Work
Remember when you first tried to parse text?
My early BASIC programs were littered with IF statements that dissected strings using LEFT$, RIGHT$, MID$, TRIM$, and UCASE$. It took me hours to write a program that parsed a simple text file. Just trying to support whitespace and mixed casing was enough to drive me crazy.
Years later when I started programming in Java, I discovered the StringTokenizer class. I thought it was a huge leap forward. I no longer had to worry about whitespace. However, I still had to use functions like “substring” and “toUpperCase”, but I thought that was as good as it could get.
And then one day I found regular expressions.
I almost cried when I realized that I could replace parsing code that took me hours to write with a simple regular expression. It still took me several years to become comfortable with the syntax, but the learning curve was worth the power obtained.
And yet with all of this love, I still had this nagging suspicion that I was doing it wrong. After reading Pragmatic Thinking and Learning, I was determined to try to imagine what life was like inside the code I wrote. But I just couldn’t connect with a regular expression.
The last straw came recently when I was trying to help a coworker craft a regex to properly handle name/value string pairs with escaped strings. In the end, our regex worked, but I felt that it was duct-taped together. I knew there was a better way.
 I picked up a copy of Jeffrey Friedl’s book “Mastering Regular Expressions” and couldn’t put it down. In less than a week, I had flown through 400+ pages and had finally started to feel like I understood how regular expressions worked. I finally had a sense for what backtracking really meant and I had a better idea for how a regex could go catastrophically out of control.
I picked up a copy of Jeffrey Friedl’s book “Mastering Regular Expressions” and couldn’t put it down. In less than a week, I had flown through 400+ pages and had finally started to feel like I understood how regular expressions worked. I finally had a sense for what backtracking really meant and I had a better idea for how a regex could go catastrophically out of control.
I had extremely high hopes for chapter 9 which covered the .NET regular expression “flavor.” Since I work with .NET every day, I thought this would be the best chapter. I did learn a few things like how to properly use RegexOptions.ExplicitCapture, how to use the special per-match replacement sequences that Regex.Replace offers, how to save compiled regular expressions to a DLL, and how to match balanced parentheses – a feat that’s theoretically not possible with a regex. Despite learning all of this in the chapter, I still didn’t feel that I could “connect” with the very .NET regular expression engine that I know and love.
To be fair, the vast benefit of the book comes from the first six chapters that deal with how regular expressions work in general since regex implementations share many ideas. The book laid a solid foundation, but I wanted more.
I wanted to stop all my hand-waving at regular expressions and actually understand how they really work.
I knew I wanted to drill into the code. Although tools like Reflector are amazing, I knew I wanted to see the actual code. It’s fairly easy now to step into the framework source code in the debugger. Unlike understanding the details of locking, which had me dive into C++ and x86 assembly, it was refreshing to see that the .NET regular expression engine was written entirely in C#.
I decided to use a really simple regular expression and search string and then follow it from cradle to grave. If you’d like to follow along at home, I’ve linked to relevant lines in the .NET regular expression source code.
My very simple regex consisted of looking for a basic URL:
string textToSearch = "Welcome to http://www.moserware.com/!";
string regexPattern = @"http://([^\s/]+)/?";
Match m = Regex.Match(textToSearch, regexPattern);
Console.WriteLine("Full uri = '{0}'", m.Value);
Console.WriteLine("Host ='{0}'", m.Groups[1].Value);Our journey begins at Regex.Match where we checking an internal cache of the past 15 regex values to see if there a match for:
"0:ENU:http://([^\\s/]+)/?"
This is a compact representation of:
RegexOptions : Culture : Regex pattern
The regex doesn’t find this in the cache, so it starts scanning the pattern. Note that out of respect for the authors, our regex pattern doesn’t have any comments or whitespace in it:
// It would be nice to get rid of the comment modes, since the
// ScanBlank() calls are just kind of duct-taped in.We start creating an internal tree representation of the regex by adding a multi-character (aka “Multi”) node to contain the “http://” part. Next, we see that the scanner made it to first real capture:
http://([^\s/]+)/?
This capture contains a character class that says that we don’t want to match spaces or a forward slash. It is converted into an obscure five character string:
"\x1\x2\x1\x2F\x30\x64"
Later we’ll see why it had to all fit in one string, but for now we can use a helpful comment to decode each character:
| Offset | Hex Value | Meaning |
|---|---|---|
| 0 | 0x01 | The set should be negated |
| 1 | 0x02 | There are two characters in the character part of the set |
| 2 | 0x01 | There is one Unicode category |
| 3 | 0x2F | Inclusive lower-bound of the character set. It’s a ‘/’ in Unicode |
| 4 | 0x30 | Exclusive upper-bound of the character set. It’s a ‘0’ in Unicode |
| 5 | 0x64 | This is a magic number that means the “Space” category. |
Before I realized that this string had meaning, I was utterly confused.
As we continue scanning, we find a ‘+’ quantifier:
http://([^\\s/]+)/?
This is noted as a Oneloop node since it’s a “loop” of what came before (e.g. the character class set). It has arguments of 1 and Int32.MaxValue to denote 1 or more matches. We see that the next character isn’t a ‘?’, so we can assert this is not a lazy match which means it’s a greedy match.
The first group is recorded when we hit the ‘)’ character. At the end of the pattern, we note a One (character) node for the ‘/’ and we see it’s followed by a ‘?’ which is just another quantifier, this time with a minimum of 0 and a maximum of 1.
All those nodes come together to give us this “RegexTree:”
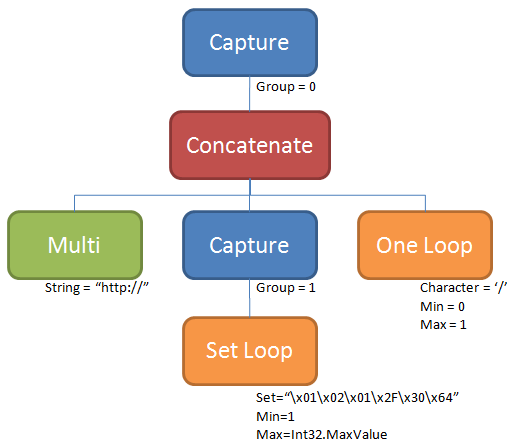
We still need to convert the tree to code that the regular expression “machine” can execute later. The bulk of the work is done by an aptly named RegexCodeFromRegexTree function that has a decent comment:
/*
* The top level RegexCode generator. It does a depth-first walk
* through the tree and calls EmitFragment to emits code before
* and after each child of an interior node, and at each leaf.
*
* It runs two passes, first to count the size of the generated
* code, and second to generate the code.
*
* <CONSIDER>we need to time it against the alternative, which is
* to just generate the code and grow the array as we go.</CONSIDER>;
*/I love the anonymous “CONSIDER” comment and would have had a similar reaction. Instead of using an ArrayList or List<int> to store the op codes, which can automatically resize as needed, the code diligently goes through the entire RegexTree twice. The class is peppered with “if(_counting)” expressions that just increase a counter by the size they will use in the next pass.
As predicted by the comment, the bulk of the work is done by the 250 line switch statement that makes up the EmitFragment function. This function breaks up RegexTree “fragments” and converts them to a simpler RegexCode. The first fragment is:
EmitFragment(nodetype=RegexNode.Capture | BeforeChild, node=[RegexNode.Capture, Group=0, Length=-1], childIndex=0)
This is shorthand for emitting the RegexCode that should come before the children of the top level “RegexNode.Capture” node that represents group 0 and that goes until the end of the string (e.g. has length -1). The last 0 means that it’s the 0th child of the parent node (this is sort of meaningless since it has no parent). The subsequent calls walk the rest of the tree:
EmitFragment(RegexNode.Concatenate | BeforeChild, [RegexNode.Concatenate], childIndex=0) EmitFragment(RegexNode.Multi, [RegexNode.Multi, string="http://"], childIndex=0) EmitFragment(RegexNode.Concatenate | AfterChild, [RegexNode.Concatenate], childIndex=0) EmitFragment(RegexNode.Concatenate | BeforeChild, [RegexNode.Concatenate], childIndex=1) EmitFragment(RegexNode.Capture | BeforeChild, [RegexNode.Capture, Group=1, -1], childIndex=0) EmitFragment(RegexNode.SetLoop, [RegexNode.SetLoop, min=1, max=Int32.MaxValue], childIndex=0) EmitFragment(RegexNode.Capture | AfterChild, [RegexNode.Capture, Group=1, Length=-1], childIndex=0) EmitFragment(RegexNode.Concatenate | AfterChild, [RegexNode.Concatenate], childIndex=1) EmitFragment(RegexNode.Concatenate | BeforeChild, [RegexNode.Concatenate], childIndex=2) EmitFragment(RegexNode.Oneloop, [RegexNode.Oneloop, min=0, max=1, character='/'], childIndex=0) EmitFragment(RegexNode.Concatenate | AfterChild, [RegexNode.Concatenate], childIndex=2) EmitFragment(RegexNode.Capture | AfterChild, [RegexNode.Capture, Group=0, Length=-1], childIndex=0)
The reward for all this work is an integer array that describes the RegexCode “op codes” and their arguments. You can see that some instructions like “Setrep” take a string argument. These arguments point to offsets in a string table. This is why it was critical to pack everything about a set into the obscure string we saw earlier. It was the only way to pass that information to the instruction.
Decoding the code array, we see:
| Index | Instruction | Op Code/Argument | String Table Reference | Description |
| 0 | Lazybranch | 23 | Lazily branch to the Stop instruction at offset 21. | |
| 1 | 21 | |||
| 2 | Setmark | 31 | Push our current state onto a stack in case we need to backtrack later. | |
| 3 | Multi | 12 | Perform a multi-character match of string table item 0 which is 'http://'. | |
| 4 | 0 | "http://" | ||
| 5 | Setmark | 31 | Push our current state onto a stack in case we need to backtrack later. | |
| 6 | Setrep | 2 | Perform a set repetition match of length 1 on the set stored at string table position 1, which represents [^\s/]. | |
| 7 | 1 | "\x1\x2\x1\x2F\x30\x64" | ||
| 8 | 1 | |||
| 9 | Setloop | 5 | Match the set [^\s/] in a loop at most Int32.MaxValue times. | |
| 10 | 1 | "\x1\x2\x1\x2F\x30\x64" | ||
| 11 | 2147483647 | |||
| 12 | Capturemark | 32 | Capture into group #1, the string between the mark set by the last Setmark and the current position. | |
| 13 | 1 | |||
| 14 | -1 | |||
| 15 | Oneloop | 3 | Match Unicode character 47 (a '/') in a loop for a maximum of 1 time. | |
| 16 | 47 | |||
| 17 | 1 | |||
| 18 | Capturemark | 32 | Capture into group #0, the contents between the first Setmark instruction and the current position. | |
| 19 | 0 | |||
| 20 | -1 | |||
| 21 | Stop | 40 | Stop the regex. |
We can now see that our regex has turned into a simple “program” that will be executed later.
Prefix Optimizations
We could stop here, but we’d miss the fun “optimizations.” With our pattern and search string, the optimizations will actually slow things down, but the code generator is oblivious to that. The basic idea behind prefix optimizations is to quickly jump to where the match might start. It does this by using a RegexFCD class that I’m guessing stands for “Regex First Character Descriptor.”
With our regex, the FirstChars functions notices our “http://” ‘Multi’ node and determines that any match must start with an ‘h’. If we had alternations, the first character of each alternation would be added to make a limited set of potential first characters. With this optimization alone, we can skip all characters in the text that aren’t in this approved “white list” of first characters without having to execute any of the above RegexCode.
But wait… there’s an even trickier optimization! The optimizer discovers that the first thing the regex must match is a simple string literal: a ‘Multi’ node. This means that we can use the RegexBoyerMoore class which applies the Boyer-Moore search algorithm.
The key insight is that we don’t have to check each character of the text. We only need to look at last character to see if it’s even worth checking the rest.
For example, if our sample text is “Welcome to http://www.moserware.com/!” and we’re searching for “http://” which is 7 characters, we first look at the 7th character of the text which is ‘e’. Since ‘e’ is not the 7th character of what we’re looking for (which is a ‘/’), we know that there couldn’t possibly be a match and so we don’t need to bother checking all previous 6 characters because there isn’t even an ‘e’ in what we’re looking for. The tricky part is what to do if the what we find is in the string that we’re trying to match, but it isn’t the last ‘/’ character.
The specifics are handled in straightforward way with some minor optimizations to reduce memory needs given 65,000+ possible Unicode characters. For each character, the maximum possible skip is calculated.
For “http://”, we come up with this skip table:
| Character | Characters to skip ahead |
|---|---|
| / | 0 |
| : | 2 |
| h | 6 |
| p | 3 |
| t | 4 |
| all others | 7 |
This table tells us that if we find an ‘e’ then we can skip ahead 7 characters without even checking the previous 6 characters. If we find a ‘p’, then we can skip ahead at least 3 characters before performing a full check, and if we find a ‘/’ then we could be on the last character and need to check other characters (e.g. skip ahead 0).
There is one more optimization that looks for anchors, but none apply to our regex, so it’s ignored.
We’re done! We made it to the end of the RegexWriter phase. The “RegexCode” internal representation consists of these critical parts:
- The regex code we created.
- The string table derived from the regex that the code uses (e.g. our “Multi” and “Setrep” instructions have string table references).
- The maximum size of our backtracking stack. (Ours is 7, this will make more sense later.)
- A mapping of named captures to their group numbers. (We don’t have any in our regex, so this is empty.)
- The total number of captures. (We have 2.)
- The RegexBoyerMoore prefix that we calculated. (This applies to us since we have a string literal at the start.)
- The possible first characters in our prefix. (In our case, we calculated this to be an ‘h’.)
- Our anchors. (We don’t have any.)
- An indicator whether this should be a RightToLeft match. (In our case, we use the default which is false.)
Every regex passes through this step. It applies to our measly regex with a code size of 21 as much as it does to a gnarly RFC2822 compliant regex that has 175. These nine items completely describe everything that we’ll do with our regex and they never change.
In need of an interpreter
Now that we have the RegexCode, the match method will run and create a RegexRunner which is the “driver” for the regex matching process. Since we didn’t specify the “Compiled” flag, we’ll use the RegexInterpreter runner.
Before the interpreter starts scanning, it notices that we have a valid Boyer-Moore prefix optimization and it uses it to quickly locate the start of the regex:
| Index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 |
| Character | W | e | l | c | o | m | e | t | o | h | t | t | p | : | / | / | w | w | w | . | m | o | s | e | r | w | a | r | e | . | c | o | m | / | ! | ||
| Scan Order | 1 | 9 | 8 | 2 & 7 | 6 | 5 | 4 | 3 |
It first looks at the 7th character and finds an ‘e’ instead of the ‘/’ that it wanted. The skip table tells it that ‘e’ isn’t in any possible match, so it jumps ahead 7 more characters where it finds a ‘t’. The skip table tells it to jump ahead 4 more characters where it finally finds the ‘/’ it wanted. It then verifies that this is the last character of our “http://” prefix. With a valid prefix found, we prepare for a match in case we’re lucky and the rest of the regex matches.
The bulk of the interpreter is in its “Go” method which is a 700 line switch statement that interprets the RegexCode we created earlier. The only interesting part is that the interpreter keeps two stacks to keep its state in case it needs to backtrack and abandon a path it took. The “run stack” records where in the search string an operation begins while the “run track” records the RegexCode instruction that could potentially backtrack. Any time there is a chance that the interpreter could go down a wrong path, it pushes its state onto these stacks so that it can potentially try something else later.
On our string, the following instructions execute:
- Lazybranch - This is a branch that is “lazy.” It will only occur if we fail and have to backtrack to this instruction. In case there are problems, we push 11 (the string offset to the start of “http://”) onto the “run stack” and 0 (the RegexCode offset for this instruction) onto the “run track.” The branch is to code offset 21 which is the “Stop” instruction.
- Setmark - We save our position in case we have to backtrack.
- Multi - A multi-character match. The string to match is at offset 0 in the string table (which is “http://”).
- Setmark - Another position save in case of a backtrack. Since the Multi code succeeded, we push our “run stack” offset of 18 (the start of “www.”) and our “run track” code position of 5
- Setrep - Loads the “\x1\x2\x1\x2F\x30\x64” set representation at offset 1 in the string table that we calculated earlier. It reads an operand from the execution stack that we should verify that the set repeats exactly once. It calls CharInClassRecursive that does the following:
- It sees that the first character, ‘w’, is not in the character range [’/’, ‘0’). This check corresponds to the ‘/’ in the “[^\s/]” part of the regex.
- It next tries CharInCategory which notes that ‘w’ is part of the “LowercaseLetter” UnicodeCategory. The magic number 0x64 in our set tells us to do a Char.IsWhiteSpace check on it. This too fails.
-
Although both checks fail, the interpreter sees that it needs to flip the result since it is a negated (^) set. This makes the character class match succeed.
- Setloop - A “loop” instruction is like a “rep” one except that it isn’t forced to match anything. In our case, we see that we loop for a maximum of Int32.MaxValue times on the same set we saw in “Setrep.” Here you can see that the code generation phase turned the “+” in “[^\s/]+” of the regex into a Setrep of 1 followed by a Setloop. This is equivalent to “[^\s/][^\s/]*”. The loop keeps chomping characters until it finds the ‘/’ which causes it to call BackwardNext() which sets the current position to just before the final ‘/’.
- CaptureMark - Here we start capturing group 1 by popping the “run stack” which gives us 18. Our current offset is 35. We capture the string between these two positions, “www.moserware.com”, and keep it for later use in case the entire regex succeeds.
- Oneloop - Here we do a loop at most one time that will check for the ‘/’ character. It succeeds.
- CaptureMark - We capture into group 0 the value between the offset on the “run stack”, which is 11 (the start of “http://”), and the last character of the string at offset 36. The string between these offsets is “http://www.moserware.com/”.
- Stop - We’re done executing RegexCode and can stop the interpreter.
Since we stopped with successful captures, the Match is declared a success. Sure enough, if we look at our console window, we see:
Full uri = 'http://www.moserware.com/'
Host ='www.moserware.com'
Backtracking Down Unhappy Paths
I can hear the cursing shouts of ^#!@.*#!$ from the regex mob coming towards me. They’re miffed that I used a toy regular expression with a pathetically easy search text that didn’t do anything “interesting.”
The mob really shouldn’t be that worried. We already have all the essential tools we need to understand how things work.
One common issue that you have to deal with in a “real” regular expression is backtracking.
Let’s say you have a search text and pattern like this:
string text = "This text has 1 digit in it";
string pattern = @".*\d"; Regex.Match(text, pattern);You’d recognize the parse tree:
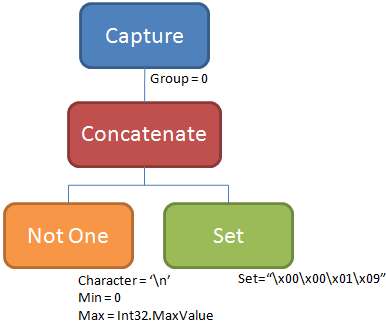
The only thing new about it is that the ‘.’ pattern was translated into a “Notone” node that matches anything except one particular character (in our case, a line feed). We see that the set follows the obscure, but compact representation. The only thing new to report is that ‘\x09’ is the magic number to represent all Unicode digits (which the Turkey Test showed is more than just [0-9]).
It’s painful to watch the regex interpreter work so hard for this match. The “.*” puts it in a Notoneloop that goes right to the end of the string since it doesn’t find a line feed (‘\n’). It then looks for the Set that represents “\d” and it fails. It has no choice but to backtrack by executing the “RegexCode.Notoneloop | RegexCode.Back” composite instruction which backtracks one character by resetting the “run track” to be the Set instruction again, but this time it will start one character earlier.
Even in our insanely simple search string, the interpreter has to backtrack by executing “RegexCode.Notoneloop | RegexCode.Back” and retesting the Set a total of thirteen times.
An almost identical process occurs if we had used a lazy match regular expression like “.*?\d”. The difference is that it does a “Notonelazy” instruction and then gets caught up in a “RegexCode.Notonelazy | RegexCode.Back” backtrack and Set match attempt that happens fourteen times. Each iteration of the loop causes the “Notonelazy” instruction to add one more character instead of removing one like the “Notoneloop” instruction had to. This is typical:
In situations where the decision is between “make an attempt” and “skip an attempt,” as with items governed by quantifiers, the engine always chooses to first make the attempt for greedy quantifiers, and to first skip the attempt for lazy (non-greedy) ones. Mastering Regular Expressions, p.159
If we had a little more empathy for the regex interpreter, we would have written “[^\d]*\d” and avoided all the backtracking, but it wouldn’t have shown this common error.
Alternations such as “hello|world” are handled with backtracking. Before each alternative is attempted, the current position is saved on the “run track” and “run stack.” If the alternate fails, the regex engine resets the position to what it was before the alternate was tried and the next alternate is attempted.
Now, we can even understand how more advanced concepts like atomic grouping work. If we use a regex like:
\w+:
to match the names of email headers as in:
Subject: Hello World!
Things will work well. The problem will come when we try to match against
Subject
We already know that there is going to be a backtracking since “\w+” will match the whole string and then backtracking will occur as the interpreter desperately tries to match a ‘:’. If we used atomic grouping, as in:
(?>\w+):
We would see that the generated RegexCode has two extra instructions of Setjump and Forejump in it. These instructions tell the interpreter to do unconditional jumps after matching the “\w+”. As the comment for “Forejump” indicates, these unconditional jumps will “zap backtracking state” and be much more efficient for a failed match since backtracking won’t occur.
Loose Ends
There are some minor details left. The first time you use any regex, a lot of work goes on initializing all the character classes that are stored as static variables. If you just timed a single Regex, your numbers would be highly skewed by this process.
Another common issue is whether you should use the RegexOptions.Compiled flag. Compiling is handled by the RegexCompiler class. The interesting aspects of the IL code generation is handled exactly like the interpreter, as indicated by this comment:
/*
* The main translation function. It translates the logic for a single opcode at
* the current position. The structure of this function exactly mirrors
* the structure of the inner loop of RegexInterpreter.Go().
*
* The C# code from RegexInterpreter.Go() that corresponds to each case is
* included as a comment.
*
* Note that since we're generating code, we can collapse many cases that are
* dealt with one-at-a-time in RegexIntepreter. We can also unroll loops that
* iterate over constant strings or sets.
*/We can see that there is some optimization in the generated code. The down side is that we have to generate all the code regardless of if we use all of it or not. The interpreter only uses what it needs. Additionally, unless we use Regex.CompileToAssembly to save the compiled code to a DLL, we’ll end up doing the entire process of creating the parse tree, RegexCode, and code generation at runtime.
Thus, for most cases, it seems that RegexOptions.Compiled isn’t worth the effort. But it’s good to keep in mind that there are exceptions when performance is critical and your regex can benefit from it (otherwise, why have the option at all?).
Another option is RegexOptions.IgnoreCase that makes everything case insensitive. The vast majority of the process stays the same. The only difference is that all instructions that compare characters will convert each System.Char to lower case, mostly using the Char.ToLower method. This sounds reasonable, but it’s not quite perfect. For example, in Koine Greek, the word for “moth” goes from uppercase to lowercase like this:
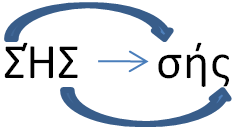
That is, in Greek, when a “sigma” (Σ) appears in lowercase at the end of a word, it uses a different letter (ς) than if it appeared anywhere else (σ). RegexOptions.IgnoreCase can’t handle cases that need more context than a single System.Char even though the string comparison functions can handle this. Consider this example:
string mothLower = "σής";
string mothUpper = mothLower.ToUpper(); // "ΣΉΣ"
bool stringsAreEqualIgnoreCase = mothUpper.Equals(mothLower, StringComparison.CurrentCultureIgnoreCase); // true
bool stringsAreEqualRegex = Regex.IsMatch(mothLower, mothUpper, RegexOptions.IgnoreCase); // falseThis also means that .NET’s Regex won’t do well with characters outside the Basic Multilingual Plane that need to be represented by more than one System.Char as a “surrogate pair.”
I bring all of these “cases” up because it obviously troubled one of the Regex programmers who wrote this comment twice:
// We do the ToLower character by character for consistency. With surrogate chars, doing
// a ToLower on the entire string could actually change the surrogate pair. This is more correct
// linguistically, but since Regex doesn't support surrogates, it's more important to be
// consistent.You can tell the author was fully anticipating the bug reports that eventually came as a result of this decision. Unfortunately, due to the way the code is structured, changing this behavior would take a hefty overhaul of the engine and would require a massive amount of regression testing. I’m guessing this is the reason why it won’t be coming in a service pack anytime soon.
The last interesting option that affects most of the code is RegexOptions.RightToLeft. For the most part, this affects where the searching starts and how a “bump” is applied. When the engine wants to move forward or get the characters to the “right”, it checks this option to see if it should move +1 or -1 character from the current position. It’s a simple idea, but its implementation is with many “if(!runrtl)” statements spread throughout the code.
Finally, you might be interested in how Mono’s regular expression compares with Microsoft’s. The good news is that the code is also available online as well. In general, Mono’s implementation is very similar. Here are some of the (minor) differences:
- Mono’s parse tree has a similar shape, but it uses more strongly typed classes. For example, sets such as [^\s/] are given their own class rather than encoded as a single string.
- The Boyer-Moore prefix optimization is done in the QuickSearch class. It is calculated at run-time and is only used if the search string is longer than 5 characters.
- The regex machine doesn’t have a separate string table for referencing strings like “http://”. Each character is passed in as an argument to the instruction.
Conclusion
Weighing in around 14,000 lines of code, .NET’s regular expression engine takes awhile to digest. After getting over the shock of its size, it was relatively straightforward to understand. Seeing the real source code, with its occasional funny comments, provided insight that Reflector simply couldn’t offer. In the end, we see that a .NET regular expression pattern is simply a compact representation for its internal RegexCode machine language.
This whole process has allowed me to finally connect with regular expressions and give them a splash of empathy. Seeing the horror of backtracking first hand in the debugger was enough for me to want to do everything in my power to get rid of it. Following the translation process down to the RegexCode level clued me into how my regex pattern will actually execute. Feeling the wind fly by a regex using the Boyer-Moore prefix optimization has encouraged me to do whatever I can to put string literals at the front of a pattern.
It’s all these little things that add up to a blazingly fast regular expression.